延續昨天的十六進位轉換,還有件重要的事。
若是某個需求,資料傳送過程中不允許傳送中文,僅能以英數字傳送,那麼我們有機會將原本的中文透過上述方式轉換成十六進位格式的字串進行傳送,如此一來可以解決傳送方式的限制或者是未知編碼錯誤的亂碼問題。
但是這裡有一個隱藏的容量成本需要考量一下。
print(len(ch_01_ba_encoded)) # ch_01_ba_encoded為:b'\xe6\xb0\xb8\xe8\xb1\x90API'
# 長度為 9 bytes
print(len(ch_hex_01_str_encoded)) # ch_hex_01_str_encoded為:'e6b0b8e8b190415049'
# 長度為 18 bytes
以上面為例,「永豐API」這幾個中英文夾雜的utf-8,剛剛有說過這串總共佔了9 bytes。
但是轉換成十六進位型態的字串,長度卻變成了18 bytes,足足變大了1倍,這是怎麼回事呢?
原因是,原本的每一個ASCII都佔1 byte,或者中文轉成3 bytes後,1個Byte是8 bits,而8 bits其實可以拆成4 + 4 bits來看。
4個Bits指的是2的4次方,其可表示的數值範圍為0~15,恰恰好就是十六進位的表示範圍。
因此每一個byte,會拆成以2個十六進位方式顯示。
我們若直接將「永豐API」這幾個utf-8的字串轉成真正bytearray的二進位,其實是長這個樣子: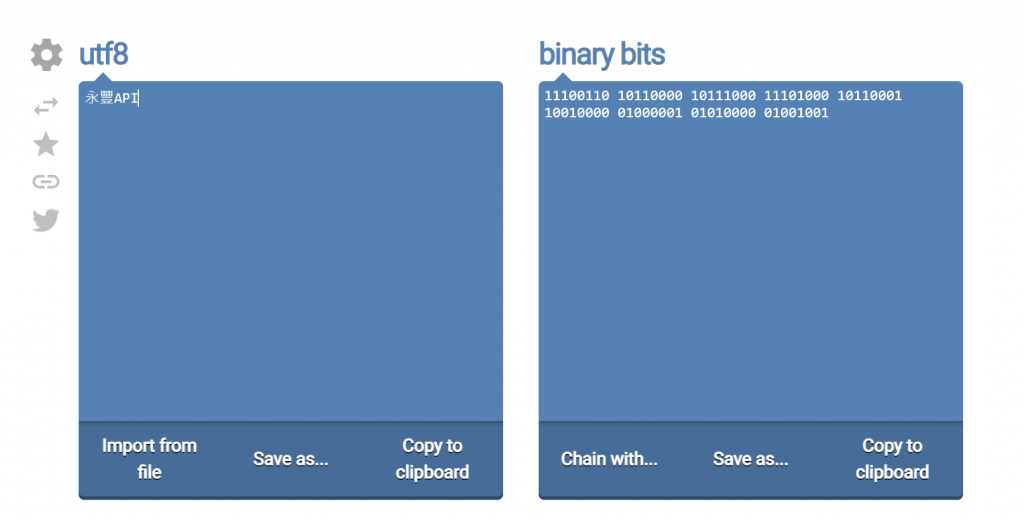
我們就拿第一個byte來看:11100110,這裡其實就只有8 bits的空間。
但剛剛說到每4個bits就可解析一個完整的十六進位,因此上述可拆成1110與0110。
而1110以10進制來看,為14,而在十六進制就是"e"。0110以10進制來看,為6,而在十六進制就是"6"。
還記得我們前面將「永豐API」這幾個字串轉出來的十六進位嗎? e6b0b8e8b190415049,前面兩位就是e6。
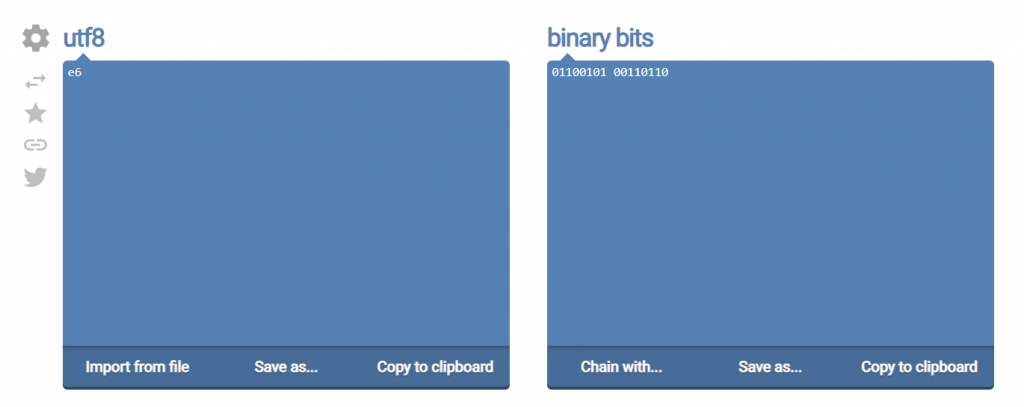
那e6這個原本從8 bits拆解出來的值,若硬生生要將2個字元輸出時,實際上佔用空間是2 bytes (16 bits)。(輸出為:01100101 00110110)因此使用這個方式,會造成傳送量直接放大一倍,是成效較低的作法。
畫個圖來說明,應該會比較好懂。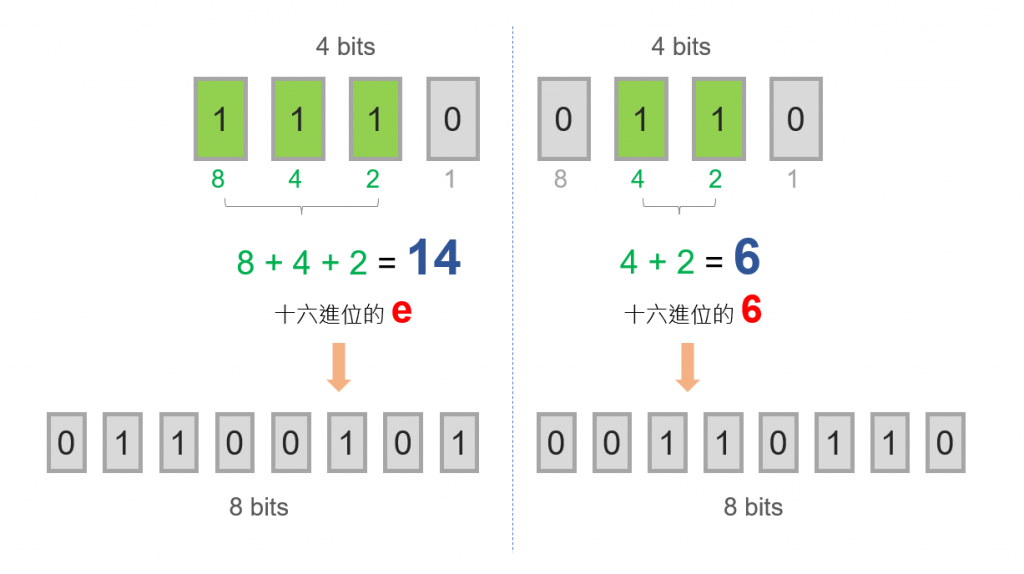
若使用Base64的編碼方式,一樣可取其均為可視字元,不會造成亂碼之外,空間耗用也較十六進位節省的多。目前廣泛被運用在許多網頁傳參數或API傳送運用上,甚至可作為網頁圖片的運用。
既然都提到Base64了,就很快速的說明一下。先前提到十六進位,如果拿來做為傳輸用途,有一個好處是他使用了數字0~9以及英文A~F (先不管大小寫)。總之,他若拿來當作字串傳遞使用,裡面的每一個字元的字就只會在這16個範圍內,當然他們都是可列印字元。不過缺點剛剛上面已說明,這樣子容量會立刻變成2倍大。
所謂16進位,就是使用了4-bit的二進位制 (2的4次方),可從裡面表示出0~15的值域。而Base64則是使用了6-bit的方式(2的6次方),因此可表示出0~63範圍內的64種值域。
這64個值域都會是可列印字元,好處先前已說過,是這樣來的:
數字0~9,10個
小寫英文a~z,26個
大寫英文A~Z,26個
上面加起來,一共是62個了
再加上兩個可列印字元+與/
總共就有64個值域可使用。
接下來實作說明一下,由於Base64採用了6-bit去切割元本的bytes,因此另外需要考慮的是若無法被剛好整除的話,最右側尾碼要補0並轉出時帶入=標示為padding用途。
附上一張Wikipedia的圖表作解說: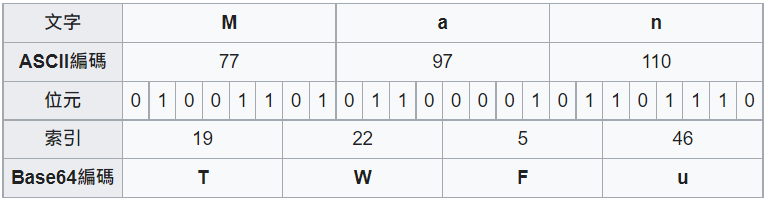
Wikipedia的Base64 索引表: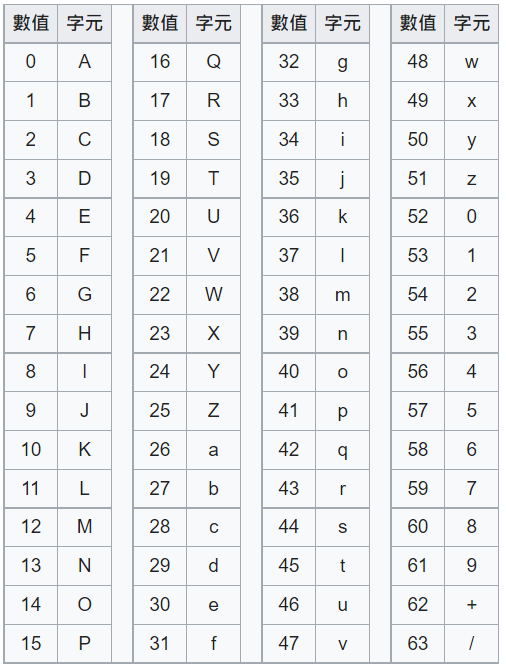
為了方便理解,我直接舉一個可以被3 bytes整除的例子(因為6與8的最小公倍數是24 bits,即3 bytes)。
若原本有3 bytes (24 bits)的資料,若以十六進位的方式每4-bit切割法會產生6個十六進位值域的字元,再轉換成純字串時會佔用6 bytes (48 bits)。
若使用了Base64來切割,每6-bit進行切割,僅會切出4個Based64值域的字元,因此一樣的我們將這些可列印字元轉成一般字串輸出時,會佔用4 bytes (32 bits)。
因此:
再使用「永豐API」這個utf-8字串,先轉成binary看一下他的原始bytes模樣,之前也說過總共佔了9 bytes。
11100110 10110000 10111000 11101000 10110001 10010000 01000001 01010000 01001001

再來就是將這些binary轉換成16進位表示,結果為E6B0B8E8B190415049:
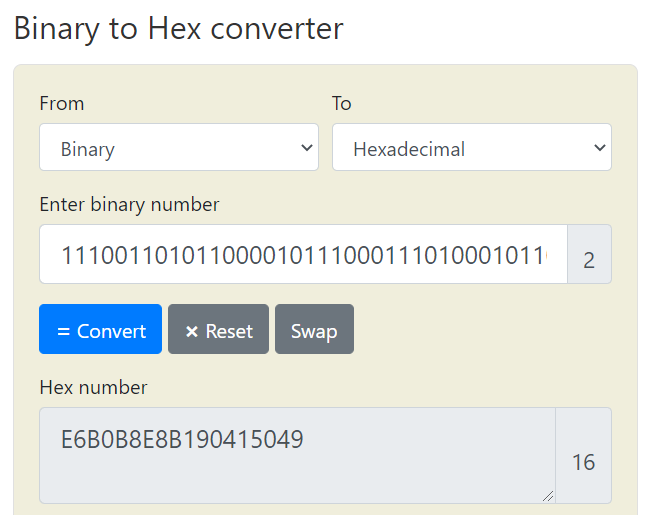
若是我們將binary轉成Base64的方式表示,結果為5rC46LGQQVBJ,光看字串就可以知道比上面十六進位短了。
接下來用Python實作一下,可以觀察其中所佔用的空間大小以及轉成字串後的增量比例。
因為有使用Base64模組,記得import base64
ch_01_str = "永豐API"
ch_01_ba_encoded = ch_01_str.encode("utf-8")
print("ch_01_ba_encoded: {}".format(ch_01_ba_encoded))
# Output: ch_01_ba_encoded: b'\xe6\xb0\xb8\xe8\xb1\x90API'
len_ori_str = len(ch_01_ba_encoded)
print("Len of ch_01_ba_encoded: {}".format(len_ori_str))
# Output: Len of ch_01_ba_encoded: 9
ch_hex_01_str_encoded = ch_01_ba_encoded.hex()
print("ch_hex_01_str_encoded: {}".format(ch_hex_01_str_encoded))
# Output: ch_hex_01_str_encoded: e6b0b8e8b190415049
len_hex_str = len(ch_hex_01_str_encoded)
print("Len of Hex String: {}, 增量:{:.2%} ".format(len_hex_str, (len_hex_str-len_ori_str)/len_ori_str))
# Output: Len of Hex String: 18, 增量:100.00%
import base64
ch_hex_01_base64 = base64.b64encode(ch_01_ba_encoded).decode("utf-8")
print("ch_hex_01_base64: {}".format(ch_hex_01_base64))
# Output: ch_hex_01_base64: 5rC46LGQQVBJ
len_base64_str = len(ch_hex_01_base64)
print("Len of Base64 String: {}, 增量:{:.2%} ".format(len_base64_str, (len_base64_str-len_ori_str)/len_ori_str))
# Output: Len of Base64 String: 12, 增量:33.33%
有關Base64最後在62個之外再加上的最後2個字元:+與/,這部份在某些情境上使用是會造成混淆的。側如/用在URL網址列時,就會和原本網址的/造成使用上的衝突。因此針對不同的最後2個字元選用,依情境上又有發展出不一樣的設計,例如那兩個字元改成-與_。但有一好沒兩好,如果把Base64又改用在正規表示式(Regular Expression),又會有原符號在裡面有特殊用途,因此又發展不同的適用版本。
若對此有興趣的話,可以自行實作,雖然原本是想談談十六進位表示法的字串增長,順便也把好用的Base64抓進來一起講。

